На Flickr появится каталог из 14 млн исторических изображений
Некоммерческая организация Internet Archive выложит в свой аккаунт на фотохостинге Flickr около 14 млн отсканированных страниц из архивных книг.
Отсканированные иллюстрации, страницы, схемы, карты входят в архив оцифрованных книг некоммерческой организации. На данный момент в аккаунт Internet Archive Book Images выложены 2,62 млн изображений. В подписи к каждому указаны автор, тема, книга, издательство, ссылки на другие изображения из книги, краткое описание, а также текст книги до и после иллюстрации. Все изображения распространяются свободно и не защищены авторским правом. Создатели проекта считают, что таким образом создадут визуальную историческую библиотеку, в которой пользователи смогут искать информацию через изображения. Internet Archive Book Images входит в проект Flickr по созданию открытых библиотек фотографий под названием The Commons.
Internet Archive занимается созданием библиотек для сохранения наследия интернета. Существуют отдельные библиотеки для аудио-, видео- и графических материалов, а также старого программного обеспечения, предыдущих версий различных сайтов и браузерных версий консольных игр 1970–1980 годов выпуска. Всего Internet Archive хранит около 19 ПБ данных, включая около 600 млн оцифрованных текстов из книг за последние 500 лет.
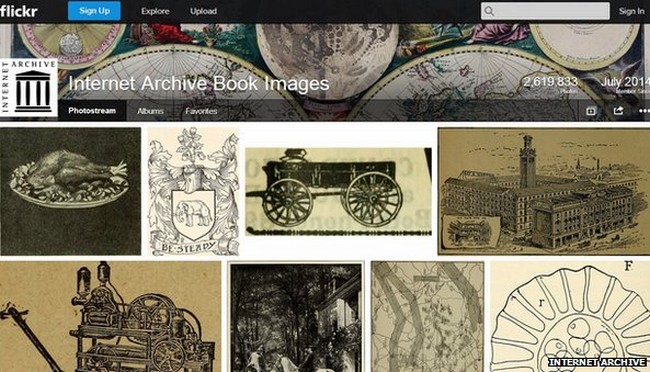
По данным источника, американский академик Калев Литару создает поисковую базу данных из 14 млн исторических изображений. Изображения датируются с 1500 до 1922 года – период, на который не распространяются ограничения в связи с авторским правом.

Господин Литару уже загрузил 2,6 млн из запланированных 14 млн фотографий на один из самых известных сервисов хранения и обмена фотографиями Flickr, где их можно легко отыскать благодаря автоматически добавленным тегам. Фотографии и рисунки были взяты из 600 млн страниц библиотечных книг, отсканированных некоммерческой организацией Internet Archive. До сих пор получить доступ к этим изображениям было достаточно непросто. По словам Калева Литару в большинстве проектов по оцифровке старых книг все внимание отводилось тексту, тогда как фотографии попросту игнорировались.
«На протяжении многих лет все библиотеки оцифровывали свои книги, но конвертировали их в PDF-файлы или текстовые документы» – рассказывает Калев Литару о своем проекте BBC. – «Они сосредоточились на книгах как на наборе слов. Этот проект меняет такой подход».
Господин Литару начал работать над проектом, исследуя коммуникационные технологии в джорджтаунском университете в Вашингтоне, в рамках гранта от компании Yahoo, являющейся владельцем сервиса Flickr. Для достижения поставленной цели была разработана программа для автоматического извлечения иллюстраций из миллионов книг в процессе OCR-сканирования, которое сейчас осуществляет Internet Archive.

Написанный господином Литару алгоритм не только позволил вернуться к ранним этапам сканирования и сохранить в формате JPEG те области страниц, которые были проигнорированы в процессе OCR-сканирования, но и добавить под каждым изображением подпись и часть текста, размещенного до и после изображения. После этого каждое изображение в формате JPEG с сопровождающим текстом из книги было размещено на новой странице Flickr, предоставляя общественности возможность исследовать огромный каталог древних иллюстраций с помощью встроенных инструментов поиска.
«Я думаю, что путешествие во времени через фотографии – одна из величайших возможностей, которой воспользуются пользователи» – сказал Калев Литару.

Каталог исторических изображений, который состоит из разнообразных пейзажей, иллюстраций по кулинарному делу, старых карт и разнообразных фотографий, от животных и транспортных средств до скульптур и зданий в различных городах, позволяет посмотреть с как менялось восприятие тех или иных вещей на временном отрезке продолжительностью 500 лет. Достаточно ввести в поиск термин, к котором у пользователя имеет определенный интерес и можно посмотреть, как та или иная вещь выглядела раньше.
«Наберите в поиск, к примеру, слово телефон, и вы увидите, что все картинки – это изображение бизнесменов, преимущественно мужчин» – объясняет Калев Литару. – «Затем вы увидите, как он превращается в инструмент, соединяющий семьи».

По словам Калева Литару, большинства иллюстраций, размещенных в книгах, нет ни в одной художественной галерее мира, а их оригиналы давно утеряны.
В рамках проекта оцифровано уже 600 млн страниц. Ожидается, что проект будет завершен в следующем году. Американский академик Калев Литару не скрывает своего желания связать его с известной интернет-энциклопедией Wikipedia.
Источник: BBC и Internet Archive